누가 딥러닝이 뭐냐고 물어보면
나는 뭐라고 해야될까
꽤나 짜릿한 질문인데
뭐라고 해야될지 미리 생각해보자
아마도 먼저
이런 거를 보여주지 않을까
머신러닝이 뭐냐고 물어보지 않기를 빌면서

그렇지 분명히 인공지능이랑 머신러닝이 뭐냐고 물어보겠지
인공지능은 말 그대로 인간의 지능을 인공적으로 만들어내는 거라고
그러면 째려보겠지..하하
컴퓨터가 인간처럼 학습할 수 있는 능력을 가질 수 있도록
연구하는 분야라고 덧붙여야겠다
그리고 머신러닝은 그림에서 확인할 수 있는 것처럼
인공지능의 한 분야인데
일반 프로그램 같은 경우에는
인간이 명령을 내려서 그대로 코드가 실행되는데
예를 들면, 어떤 숫자가 홀수인지 짝수인지 알아내고 싶다면,
일반 프로그램에서는 2의 배수가 아니면 "홀수"를 출력해라!! 이런식으로
내가 직접 코드를 설계해야되잖아
그런데 머신러닝은 홀수/짝수 찾기 문제를 해결하기 위해
스스로 규칙을 찾아서 해결해내는 거야
그리고, Machine은 기계잖아, Learning은 학습이고,
그래서 기계 학습이랑 머신러닝이랑 같은 거야
(왜 딥러닝은 깊은 학습이라고 안하..)
그리고 딥러닝은 또 머신러닝의 한 분야인데
깊은 인공신경망에 기반하여 더 복잡한 문제들을 해결할 수 있어
이게 무슨 말인지 모르겠지?
인공신경망은 인간의 뉴런을 모방하여 만든건데
일단 그림부터 보여줘야겠어

그니까 이걸로 뭐를 하는 거냐면

예를 들면,
이런식으로 입력층에
특징들을 넣어서 강아지인지 아닌 지 예측할 수 있는거야
은닉층은 여기서는 2개만 했는데
여러 개 더 추가할 수 있어
딥러닝이 '딥' 러닝인 이유는
이 은닉층이 여러 개가 쌓여서 '깊'기때문이야
인공신경망을 배우려고 한다면
'퍼셉트론'이라는 것을 먼저 만나게 될텐데
고대 인공 신경망이라고 생각하면 돼
여기에는 은닉층이 없어
이걸 잘 살펴보면 왜 은닉층이 필요한 지 알게 돼
퍼셉트론에는 한계점이 있거든
XOR 문제라고 하는데
이거는 조금만 더 있다가 알려줄게
일단은 퍼셉트론의 한계점을
은닉층을 사용해서 해결했고
이걸 다층 퍼셉트론이라고 한다는 것을 기억해줘
다층신경망이지
여기까지는 꽤나 스무스했는데
그리고 또 무슨 얘기를 해줘야될까
전체 딥러닝 학습 과정을 간단히 설명하자면

입력 데이터가 입력층과 은닉층을 거쳐
출력층까지 전달되는 과정을 순전파라고 하고
그 후에는 그 출력값(예측값)을 정답과 비교한 후
역전파를 통해 업데이트를 하게 돼
그리고 또 다시 순전파를 진행하고 또 정답과 비교하고
업데이트하고, 이런 과정을 반복하면서
더 정확한 예측을 할 수 있는
딥러닝 모델을 만드는 거야
이렇게 말하면 너무 어려울려나
그러니까 딥러닝이라는 것은
어떻게 보면
"잘 찍는 거" 라는 생각이 들어
그냥 막 찍는 거 아니고
잘 찍는 거

이런 데이터들이 있어
이 데이터를 제일 잘 나타낼 수 있는 직선을 그려봐
왜 그래야되나면
그래야 그 다음 데이터가 어디에 위치할 지 예측할 수 있으니까

기존에 있는 데이터들을 통해서
x가 t일때 데이터가 어디에 위치할 지 예측할 수 있게 돼

만약 이런 그래프를 그렸다면,
예측값과 데이터의 차이가 많이 나는 듯 해
그러면 다시 한번 그려보자

아까보다는 오차가 많이 줄었지
이게 딥러닝 학습 과정이야
오차가 더 적은 그래프를 그릴려고 하는 거지
우리는 그냥 대충 눈으로 보고
그래프를 그릴 수 있지만
컴퓨터는 이걸 어떻게 할 수 있을까
그러니까 "잘 찍는" 거야
그래프를 찍고, 오차를 확인하고
그리고 다시 찍고
이제 다시
이걸 본다면 더 잘 이해할 수 있을 거야

직선 그래프를 그린다는 말을
다르게 표현하면
y=wx + b
에서 w와 b를 찾는 거야
좀 있다가 아주 많이 볼테니까
꼭 기억하라는 말도 해줘야겠다..
w는 weight 가중치라고 하고
b는 bias 바이어스(편향)라고 해
예측 문제의 종류 (딥러닝이 해내면 좋겠는 것)에는
크게 분류와 회귀가 있어

순전파 과정으로 넘어가기 전에
아까 말했던
퍼셉트론 XOR 문제를
여기서 자세하게 설명해줄게
일단 OR, AND, 그리고 XOR이 뭔지 그림을 통해 알려줄게


퍼셉트론에서는 선형적으로 분류 가능한 문제만 해결할 수 있거든
이게 무슨 말이냐면
일단

(0,0) 일 때 0 검정으로 표현
(0,1) 일 때 1 빨강으로 표현
(1,0) 일 때 1 빨강으로 표현
(1,1) 일 때 1 빨강으로 표현
OR일 때는 저렇게 초록색 직선을 그어서
빨강과 검정을 분류할 수 있어

AND도 마찬가지로 가능하고

그런데!
XOR 같은 경우는 직선 하나로 분리가 불가능해
퍼셉트론으로 해결하지 못하는 문제가 있는거야
이걸 해결하기 위해서 은닉층이라는 것을 사용해
그래서 아까 처음에 보여줬던

이런 다층 신경망이 만들어진거야
은닉층이 없으면 딥러닝이 아니야
아까 딥러닝이 '딥' 러닝인 이유는
이 은닉층이 여러 개가 쌓여서 '깊'기때문이라고 했잖아
퍼셉트론은 머신러닝이고, 다층 퍼셉트론은 딥러닝이다
이렇게 이해해도 괜찮지 않을까
물론 지금은 기본을 배우는 거고
나중에는 다층퍼셉트론 말고도
CNN, RNN 이런 다양한 신경망 구조에 대해서 배우게 돼
그럼 어떻게 은닉층으로 XOR 문제를 해결했는 지 더 살펴보자


종이를 이렇게 휘어서
초록색 직선을 그으면
하나의 직선으로
빨간점과 검정점을 분류할 수 있게 돼
저기 저 칼을 초록색 직선이라고 생각하면 돼
2차원 평면에서
층을 하나 더 만들어서
분류하는 거야
퍼셉트론 두 개를 한 번에 계산하는 거지


이런 식으로 초록색 층을 추가하는 거야
이게 바로 은닉층이야
y의 결과는 똑같은 거 보이지?
OR NAND 그리고 다시 AND를 이용하여
XOR과 똑같은 결과를 만들어냈어
다만 중간에 한 과정, 즉 한 층을 더 추가한 거지
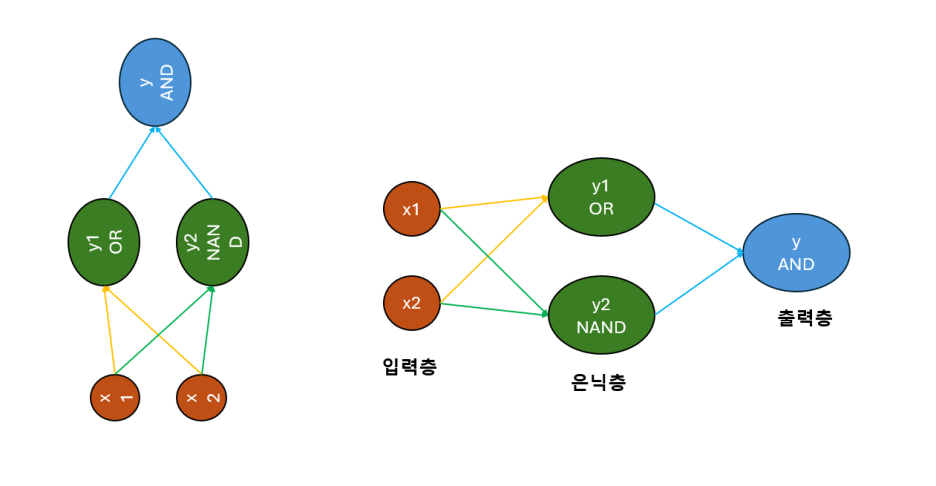
왼쪽 그림은 그냥 아까 말했듯이
층을 쌓듯이 초록색 은닉층을 추가해줬다는 것을
표현하기 위해서 보여주는 거고
이제 이런 식으로 입력층, 은닉층, 출력층을 갖춘
다층 퍼셉트론이 만들어졌네!
자 이제 순전파 과정을 좀 더 살펴볼까
영어로는 Forward Propagation이라고 해
이 과정을 살펴보면 딥러닝에서
은닉층이 왜 중요한 지 알 수 있을 거야
이걸 설명할 때 거의 모든 책에서
MNIST 데이터를 가지고 설명해
이건 필기체 숫자 이미지 데이터인데
원래는 28x28인데 쉬운 설명을 위해서
20x20 픽셀로 이루어져있다고 해보자
이 필기체 숫자가 무슨 숫자인지 맞추는 거야
이건 다중 클래스 분류 문제야


이런 식으로 해당 이미지가 어떤 숫자에 가까운 지 예측하는 거야
이미지 데이터가 가로 20 X 세로 20 이잖아 (2차원 데이터)
이미지 데이터 픽셀을 한줄로 쭉 만들어서
400개 조각이 입력층이 되는 거고 (1차원 데이터)
숫자가 총 0부터 9개니까 출력층은 10개가 돼
그 다음에는 조금 복잡할 수 있는데
아까 말했던 거를 다시 떠올려보면
그래프를 그린다는 것은
y=wx+b에서 w와 b값을 찾는 거랑 같다고 했잖아
이제 그 과정이 어떻게 진행되는 지 자세하게 알아보는 거야
x1,x2,x3.....이건 위에서 설명했듯이 입력층이고
이것들이 은닉층으로 넘어갈 때의 과정에 대해서 알려줄게
여기서 w값들은 "잘 찍은" 값들이야
그니까 지금 예측값을 내어놓는 과정으로 가고 있는 거야
우선 먼저 간단히 설명해줄게
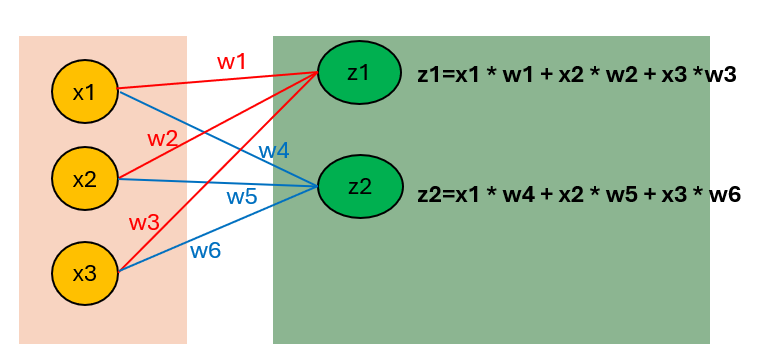
400개를 다 하기에는 너무 복잡하니 3개만 해보자면
은닉층으로 넘어갈 때 z1은 이렇게 계산이 돼

행렬 계산인데
행렬을 몰라도 위에 그림을 보면
어떻게 계산이 되는 지 알 수 있으니까 일단 괜찮아
원래 400개인데 지금 3개만 한거잖아,
그것도 지금 고작 은닉층의 첫번째 층인데
그니까 계산을 얼마나 많이 해야되는 지 알겠지?
인공지능이라고 하면
엄청 복잡한 계산을 할거라고 생각이 들 수도 있는데
사실은 이런 단순한 계산을 정말 많이 해야돼
자 그러면 이제 본격적으로 계산을 해보자

저기 저 동그라미 하나 하나를 '노드'라고 하거든
은닉층을 3개로 하고 노드의 개수를 50개,30개, 20개라고 해보자
여기서부터는 자신이 좀 없는데ㅎ..

아까는 그냥 간단히 어떻게 진행되는 지만 보여주려고 했는데
여기서는 y=wx+b 형태로 만들려고 w를 전치행렬로 만들었어
행렬에서는 AB 랑 BA는 다른거야
전치행렬은 뭐냐면

이런거야
3X2 (행X열) 크기의 행렬이
2X3 크기의 행렬이 되는거야
더 자세하게 해야되나
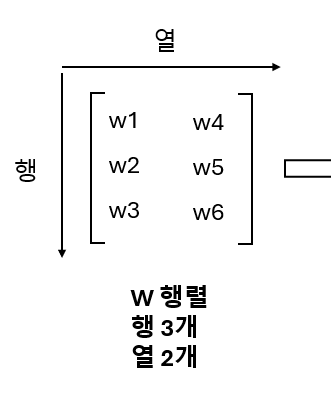
w 행렬의 크기는 3x2야
행렬의 곱셈이 가능하기 위해서는
첫번째 행렬의 열과 두번째 행렬의 행이 같아야돼
m x n 크기의 행렬과 n x p 크기의 행렬은
곱셈이 가능하지
두 행렬을 곱하면 m x p 크기의 행렬이 만들어져
아까 행렬 몰라도 일단 괜찮다고 했는데
말하다보니까 안괜찮네^^

이제 이걸 다시 보면

50 X 400 크기의 행렬과 400 X 1 크기의 행렬을 곱해서
50 X 1 크기의 행렬이 만들어졌다는 게 보일거야
(저기 R 기호는 맨날 아무 생각 없이 쓰다가
이번에 찾아봤는데 실수 집합 기호래)
자 행렬 곱 설명하다가 길을 잠깐 잃었는데
우리가 뭐를 하고 있었냐면

지금 이거 하나 한거야
갈 길이 아주 멀었어
그 다음에는 이걸 활성화함수에 넣을 건데
왜 활성화함수가 필요한지 먼저 얘기를 해야겠지

활성화 함수
영어로는 activation function이라고 해
과학시간에 뉴런 배웠던 거 생각나?
자극, 활성화 이런 단어들이 있었잖아
사실 나도 기억이 잘 안나는데
그런 느낌이야
뉴런을 모방해서 만든 인공신경망이잖아
입력으로 받은 신호의 합이 임계값을 넘을 경우에만
뉴런이 활성화 되어서 출력 신호를 발생해
아까 w는 weight 가중치
b는 bias 편향이라고 얘기했는데
이제 더 자세하게 말할 때가 온 것 같아
w 가중치
입력이 출력에 얼마 만큼 영향을 주는 지 결정해
가중치가 크면 입력 신호의 영향이 커지는 거야
예를 들면 y=4x+4 랑 y=24x+4가 있으면
x는 입력신호, 첫번째 식의 가중치는 4, 두번째 식의 가중치는 24
x=2일때 처음꺼는 4*2+4고, 두번째꺼는 24*2+4 잖아
이렇게 가중치가 큰 두번째꺼가 입력신호의 영향을 많이 받게 돼
bias 바이어스
아까 계산할때는 바이어스까지는 고려하지 않았는데
편향이라는 게 어느 한 쪽으로 치우치게 하는 거잖아
바이어스는 출력을 어느 한 쪽으로 치우치게 해서
얼마나 쉽게 활성화가 되는 지를 결정해
아까 활성화 함수 처음 설명하면서
뉴런이 임계값을 넘으면 활성화 된다고 했잖아
b가 임계값이야
x1w1 + x2w2 + x3w3 + b1 >0 이면 활성화가 된다고 하자
만약에 b가 -0.01이면 x1w1 + x2w2 + x3w3이
0.01만 넘으면 활성화가 돼
근데 b가 -100이면 x1w1 + x2w2 + x3w3 -100
왼쪽에 있는 식의 입력 신호가 다 0이 되더라도
b때문에 출력이 0이 아니게 되는거야
이런 의미로 바이어스는 출력을 어느 한 쪽으로 치우치게 해
활성화함수의 종류에는
계단함수, 시그모이드함수, 렐루함수 등이 있는데
그건 다음에 자세히 다루도록 할게
지금은 일단 과정에 집중하자고
아까 z[1] 하나 계산하는 거 까지 했었잖아
그 후 과정은 이렇게 돼

자 그러면 예측값까지 온거야
그 다음에는 오차랑 비교를 해야되잖아
그래서 손실함수를 쓰게 돼
영어로는 loss function이라고 해
손실함수에도 여러 가지 종류가 있어
평균 제곱 오차 (MSE), 교차 엔트로피 함수 등이 있어
이것도 자세한 것은 나중에 다루는 게 좋겠어
이제 역전파에 대해서 알아볼 차례가 왔어
딥러닝이란 "잘 찍는 거"라고 했었잖아
w를 제대로 찍는 게 우리의 목표였어
오차를 최소화할 수 있도록
오차를 구했다면
이제 다시 돌아가면서 수정을 해야겠지
업데이트 하는 과정이
역전파야
일단 수정을 하려면
뭘 수정해야되는 지 알아야되잖아
그러면 w의 변화가 총 오차에
얼마 만큼의 영향을 주는 지 알아야 해
오차를 커지게 하는 원인을 찾아서
그걸 줄여야되니깐
이걸 식으로 나타내면
∂L/∂W[4]T 야
편미분이라는 게 있어
여러 변수가 있을 때
어느 한 변수에 대해서만 미분을 하고
나머지 변수들은 상수 취급을 하는 거야

∂L/∂W[4]T
이제 이걸 다시 보면
총 오차(L)에서 W[4]T에 대한 미분
미분값이란, 어떤 지점에서
x를 조금 변화시켰을 때,
함수 f(x)가 그에 따라 얼마나 변하는지를 나타내는 값이거든
그러니 총 오차에서 W[4]T의 변화율을 의미하는 거야
또 다르게 말하면
총 오차가 W[4]T에 얼마나 민감하게 반응하냐를 나타내는 거고
자 그러면 이제
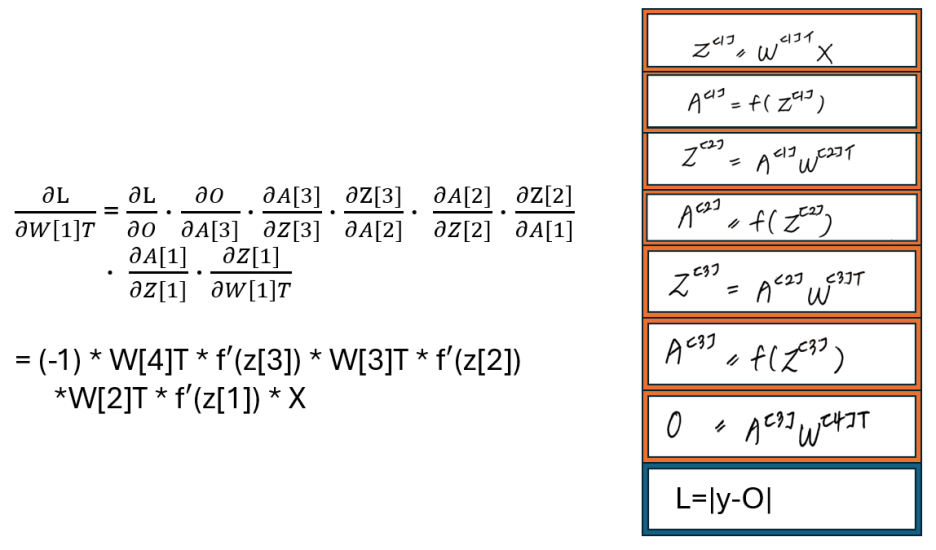
∂L/∂W[4]T 를 구해보자
이걸 구하려면 체인룰이라는 것을 알아야 돼

아마 말로 설명하는 것보다
식으로 보는 게 더 이해하기 쉬울 거야
∂L/∂W[4]T 는 모르지만
∂L/∂O 와 ∂O/∂W[4]T는 알 수 있잖아
아까 순전파를 하면서 구해놨던 식을 통해서
체인룰은
우리가 아는 것을 가지고
구해야하는 것을 알아내는 방법이야
W[1]T가 아니라 W[4]T부터 구하는 이유도
과정을 보면 알 수 있지


자 그 다음에는
최적화 문제에 대해 알아볼 차례야
영어로는 optimization이라고 해
어떤 함수를 최소로 만들거나 최대로 만드는 값을 찾는 문제야
우리의 경우에는
손실함수의 값을 최소로 하는 W값을 찾아야겠지
손실함수가 최소라는 것은
오차가 최소라는 뜻이니까
최적화 문제를 해결하기 위해
일반적으로 경사하강법을 사용해
영어로는 gradient-descent method라고 해
경사하강법은 함수의 1차 미분값을 반복적으로 사용해
여기서 함수의 1차 미분값이라는 게 gradient야
gradient를 영어사전에 검색해보면
경사도라는 뜻을 가지고 있다는 것을 알 수 있어
여기에서는 기울기를 의미하겠지
손실함수가 특정 가중치에서
얼마나 그리고 어떤 방향으로 변화하는 지 나타내
아까 ∂L/∂W[4]T, ∂L/∂W[3]T...를 왜 열심히 구한지 알겠지?
총 오차 (L)에서 W[4]T에 대한 미분이라고 했잖아
∂L/∂W[4]T, 이 미분값이 기울기를 의미해
경사하강법에서는 손실함수가 최소가 되도록
가중치 값을 업데이트 시키는 거야

왜 식이 이렇게 써지는 지 더 알아볼게
손실함수 그래프를 간단하게 나타내서
살펴보면,

만약 gradient, 기울기가 음수라면
가중치를 증가시켰을 때 손실함수의 값이 감소해
양수면 반대로
가중치를 감소시켰을 때 손실함수의 값이 감소한다는 뜻이지
gradient가 음수일때는 가중치를 증가시키고
gradient가 양수일때는 가중치를 감소시키면서
말 그대로 경사를 하강하는 거야
기울기의 반대방향으로 이동하는 거지
마치 산에서 내려가는 것처럼
목적지가 맨 밑이니 경사가 제일 낮은 지점을 향해서 가는 거지
우리의 목표는 손실함수가
최소가 되는 지점이니까

이걸 식으로 나타내면 이렇게 돼
'-'가 붙은 이유는 기울기의 반대방향으로 이동하기 때문이야
여기서 얼마만큼 이동하는 지는 학습률에 따라 결정돼
학습률이 크면 가중치가 한 번 업데이트 될 때 큰 폭으로 변하게 돼
학습률이 너무 크면
오버슈팅 같은 문제들이 생겨
그거는 또 다음에 자세하게 설명하는 게 좋겠어
일단은 학습률을 적절하게 설정해야된다는 것만 알아둬
자 이제 거의 끝이야
아까 말했듯이
이 과정을 여러 번 반복하면서
학습을 시키는 거야
모델을 학습했으면 검증 해봐야지
검증은 중간 점검 같은 거야
검증 과정에서 학습이 되지는 않아
그리고
학습이 다 끝나면 시험 데이터를 이용하여
딥러닝 모델의 최종 성능을 평가해
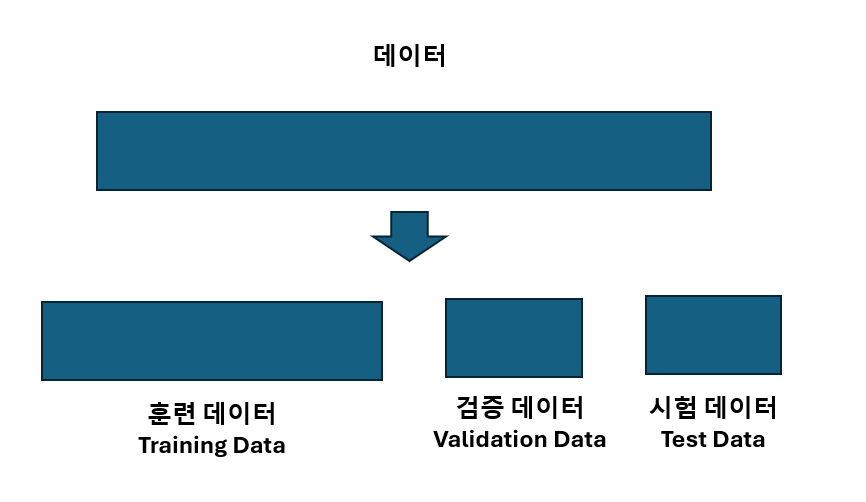
데이터를 이렇게 나누는 이유는
학습할 때 쓴 데이터(훈련 데이터)를 그대로 쓰면
그건 마치 풀었던 문제가 그대로 시험에 나오는 거잖아
접해보지 않은 새로운 문제로 시험을 봐야
성능을 정확하게 평가할 수 있겠지
이 정도로 마무리하는 걸로 하고
말하다보니까
생각보다 길어졌네
어째든,,
다음에 누가 딥러닝이 뭐냐고 물어본다면
이렇게 대답해야겠어
모든 그림, PPT로 제작
오타, 오류 제보
jyaenugu@naver.com
'딥러닝 > 뭐라고 해야될까 시리즈' 카테고리의 다른 글
| chapter 06 오토인코더가 뭐냐고 물어보면 뭐라고 해야될까 (0) | 2025.02.18 |
|---|---|
| chapter 05 RNN이 뭐냐고 물어보면 뭐라고 해야될까 (0) | 2025.01.30 |
| chapter 4 CNN이 뭐냐고 물어보면 뭐라고 해야될까 (0) | 2025.01.28 |
| chapter 3 경사 하강법이 뭐냐고 물어보면 뭐라고 해야될까 (0) | 2025.01.24 |
| chapter 2 활성화함수와 손실함수가 뭐냐고 물어보면 뭐라고 해야될까 (0) | 2025.01.23 |



